
Depuis que j’ai découvert Google Colab, mon approche de l’analyse de données et de l’apprentissage automatique a été complètement transformée. Ce service gratuit offert par Google permet d’exécuter des scripts Python directement dans le navigateur, en tirant parti des ressources cloud de l’entreprise. L’environnement Jupyter Notebook de Colab m’a ouvert de nouvelles perspectives pour manipuler efficacement de gros volumes de données et entraîner des modèles complexes. Dans ce tutoriel, je vais vous guider à travers les principales fonctionnalités de Colab pour tirer le meilleur parti de cet outil puissant. C’est parti 👇
Comment fonctionne Google Colab
La première fois que j’ai ouvert un notebook Colab, j’ai été impressionné par la simplicité et l’intuitivité de l’interface. L’environnement Jupyter familier m’a permis de me sentir rapidement à l’aise. Pour créer un nouveau notebook, il suffit de se rendre sur colab.research.google.com et de cliquer sur « Nouveau notebook ». L’interface se compose de cellules de code et de texte, d’une barre de menu et d’outils essentiels pour la gestion du notebook.
L’exécution du code Python dans les cellules est un jeu d’enfant. Il suffit de taper le code et d’appuyer sur Maj+Entrée pour voir les résultats s’afficher instantanément. J’ai particulièrement apprécié la possibilité de connecter mon Google Drive à Colab, ce qui m’a permis de sauvegarder mes travaux et d’accéder facilement à mes fichiers de données.
D’un autre côté, il faut garder à l’esprit que les sessions Colab ont une durée limitée. Après plusieurs heures d’inactivité, le runtime se déconnecte automatiquement. Pour éviter de perdre votre travail, pensez à sauvegarder régulièrement et à redémarrer le runtime si nécessaire. Cette contrainte m’a appris à structurer mes notebooks de manière plus efficace et à optimiser mon temps de travail.
Maîtriser les bibliothèques Python essentielles sur Colab
L’un des grands avantages de Colab est la facilité avec laquelle on peut installer et utiliser les bibliothèques Python les plus populaires. Pandas, NumPy, Matplotlib et TensorFlow sont préinstallés, ce qui permet de commencer à travailler immédiatement sur des projets d’analyse de données ou d’apprentissage automatique.
Pour installer d’autres bibliothèques, il suffit d’utiliser la commande !pip install dans une cellule de code. Par exemple, pour installer la bibliothèque OpenNMT, j’ai simplement exécuté :
!pip install OpenNMT-py
L’importation et l’utilisation de ces bibliothèques se font de manière classique. Voici un exemple rapide d’utilisation de Pandas pour charger un fichier CSV :
import pandas as pd<br>df = pd.read_csv('mon_fichier.csv')<br>print(df.head())
Cette simplicité d’utilisation m’a permis de me concentrer sur l’analyse plutôt que sur la configuration de l’environnement. J’ai pu passer rapidement du preprocessing des données à l’entraînement de modèles complexes comme des Transformers pour la traduction automatique.
Exploiter la puissance de Colab pour l’analyse de données
La possibilité de charger des données depuis Google Drive ou d’autres sources externes m’a permis de travailler sur des datasets variés et volumineux. J’ai souvent utilisé Colab pour fusionner plusieurs fichiers CSV, une tâche qui peut être fastidieuse sur des machines locales moins puissantes.
Le nettoyage et le filtrage des données sont des étapes cruciales dans tout projet d’analyse. Avec Pandas, j’ai pu rapidement identifier et traiter les valeurs manquantes, supprimer les doublons et appliquer des filtres complexes. Voici un exemple de code que j’utilise fréquemment pour nettoyer mes données :
df = df.dropna()<br>df = df.drop_duplicates()<br>df = df[df['colonne'] > valeur_seuil]
La création de champs calculés et l’agrégation de données sont également des opérations que j’effectue régulièrement sur Colab. Ces manipulations m’ont permis d’extraire des insights précieux de mes données brutes. Par exemple, pour calculer le taux de conversion d’une campagne marketing :
df['taux_conversion'] = df['conversions'] / df['visites'] * 100
Enfin, la visualisation des données avec Matplotlib m’a toujours impressionné sur Colab. La possibilité de créer des graphiques interactifs directement dans le notebook a grandement facilité mon travail d’analyse et de présentation des résultats.
Apprentissage automatique et entraînement de modèles avancés
L’accès gratuit aux GPUs et TPUs de Google est sans doute l’un des aspects les plus attrayants de Colab pour les projets d’apprentissage automatique. J’ai pu entraîner des modèles complexes en une fraction du temps qu’il m’aurait fallu sur mon ordinateur personnel.
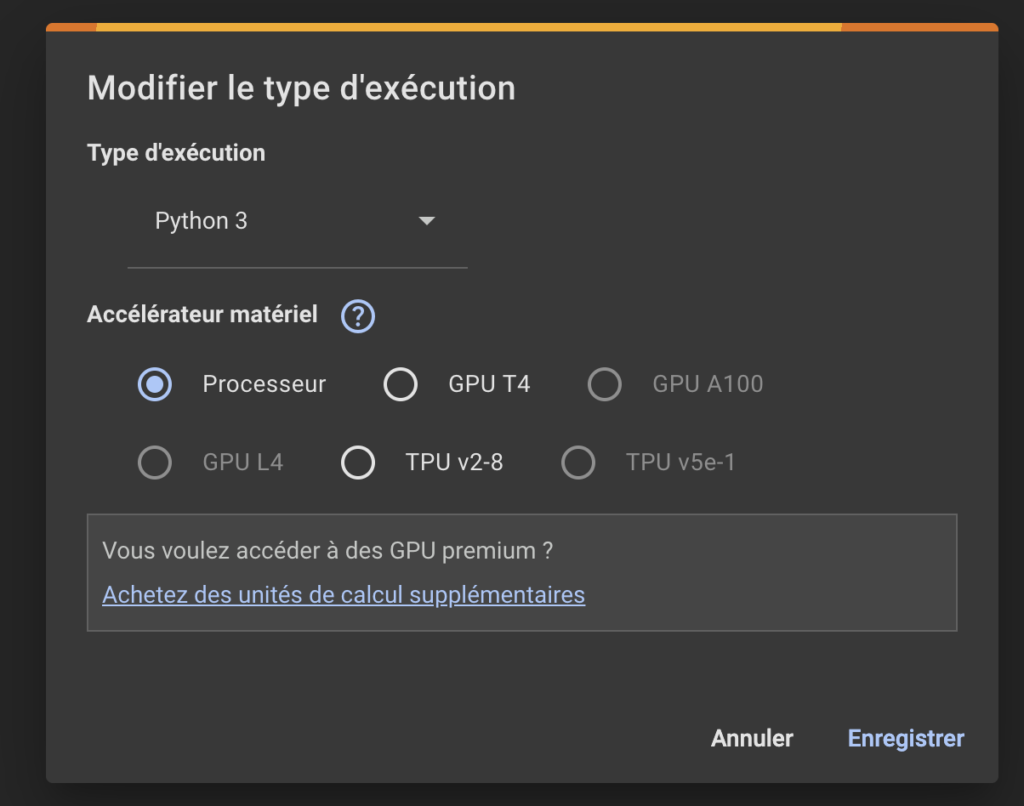
Pour activer l’accélération matérielle, il suffit d’aller dans le menu « Runtime » et de sélectionner « Change runtime type ». Choisissez ensuite GPU ou TPU selon vos besoins. Cette fonctionnalité m’a permis d’expérimenter avec des architectures avancées comme PyTorch et TensorFlow sans me soucier des limitations matérielles.
Voici un exemple simple d’entraînement d’un modèle de classification que j’ai réalisé sur Colab :
- Importer les bibliothèques nécessaires (sklearn, numpy)
- Charger et prétraiter les données
- Diviser les données en ensembles d’entraînement et de test
- Créer et entraîner le modèle
- Évaluer les performances du modèle
La sauvegarde et le chargement des modèles entraînés sont cruciaux pour éviter de perdre son travail. J’utilise généralement la bibliothèque joblib pour cette tâche :
from joblib import dump, load<br>dump(model, 'mon_modele.joblib')<br>model = load('mon_modele.joblib')
Pour éviter les timeouts lors de l’entraînement de modèles complexes, j’ai appris à utiliser des checkpoints réguliers. Cette technique m’a permis de reprendre l’entraînement là où il s’était arrêté en cas d’interruption de la session Colab.
Astuces pour maximiser l’efficacité sur Colab
Au fil de mon expérience avec Colab, j’ai développé quelques astuces pour tirer le meilleur parti de cet outil puissant. Voici mes recommandations :
- Utilisez les commandes système précédées de « ! » pour interagir avec l’environnement Linux sous-jacent
- Profitez de l’autocomplétion et de l’aide intégrée pour chercher les fonctionnalités des bibliothèques
- Utilisez la fonction %%capture pour masquer les sorties verbeuses lors de l’installation de packages
- Exploitez les widgets interactifs pour créer des notebooks dynamiques et engageants
J’ai également découvert que Colab est un excellent outil pour l’apprentissage et la formation. Sa facilité d’utilisation en fait une plateforme idéale pour les débutants en Python, tandis que ses capacités avancées satisfont les utilisateurs plus expérimentés. J’ai souvent utilisé Colab pour créer des tutoriels interactifs sur des sujets allant du preprocessing des données à l’entraînement de modèles de traduction basés sur des Transformers.
En résumé, Google Colab a transformé ma façon d’aborder l’analyse de données et l’apprentissage automatique. Sa puissance, sa flexibilité et sa gratuité en font un outil incontournable pour tout data scientist ou développeur Python. Que vous soyez débutant ou expert, Colab offre un environnement propice à l’expérimentation et à l’innovation. N’hésitez pas à l’analyser et à repousser les limites de vos projets d’analyse et de modélisation. Et si vous voulez aller encore plus loin dans l’optimisation de votre productivité, je vous recommande de découvrir comment ChatGPT change notre quotidien digital en améliorant la productivité. Cette technologie complémentaire pourrait bien révolutionner votre flux de travail, tout comme Colab l’a fait pour moi.